Agente IA para extraer automáticamente los datos de un CV (con n8n)
¿Quieres extraer automáticamente la información de un CV sin perder horas copiando y pegando? Esta automatización con n8n te ahorra tiempo gracias a un Agente IA que estructura todos los datos por ti.
La automatización completa, en tu bandeja
Agente IA para extraer automáticamente los datos de un CV (con n8n)

Extrae Automáticamente la Información Clave de un CV con un Agente IA (Workflow n8n Gratis + Video + Tutorial + Descarga)
Requisito previo: Tener una instancia de n8n self-hosted con acceso al terminal
! NecesitasRequisito previo: Tener una instancia de n8n self-hosted con acceso al terminal
- A self-hosted n8n instance with terminal access.
- API credentials for the services used in this workflow.
La automatización completa, en tu bandeja
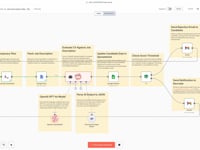
Detalle del workflow n8n.
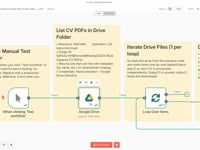
01 Paso 01Iniciar el Workflow (Manual Trigger).
Esta primera etapa te permite probar el workflow manualmente. Gracias al módulo Manual Trigger de n8n, puedes ejecutar el flujo bajo demanda para verificar que funciona correctamente antes de automatizarlo en producción.
El disparador manual es muy útil para probar cada paso en tiempo real y detectar fácilmente posibles errores. Una vez que validas tus pruebas, puedes reemplazar este disparador por uno automático (ej.: cron, webhook…) si lo necesitas.
Para empezar: haz clic en "Run Workflow" dentro de n8n para iniciar el proceso.
Parámetros- Tipo de disparador: Manual Trigger
- Uso: Ejecución manual del workflow desde la interfaz de n8n
02 Paso 02Obtener la Lista de CV desde Google Drive.
Este paso permite listar automáticamente todos los archivos PDF que están en una carpeta específica de tu Google Drive. Cada archivo corresponde a un CV que será procesado individualmente por el agente IA.
💡 Consejo : puedes obtener el ID de tu carpeta Drive en la URL cuando estés dentro de la carpeta. Es la parte que sigue a
/folders/.Parámetros- Módulo : Google Drive
- Operación : Listar todos los archivos en una carpeta
- Carpeta : ID de tu carpeta Google Drive que contiene los CV
- Autenticación : Tu cuenta Google conectada a n8n
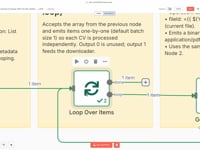
03 Paso 03Procesar los CV uno por uno (Loop).
Esta etapa utiliza el módulo Split In Batches para procesar cada CV de forma independiente. Se realiza un bucle sobre cada archivo PDF recuperado para ejecutarlo en un flujo aislado.
Esto garantiza un procesamiento limpio y evita confusiones si hay varios archivos en la carpeta.
Parámetros- Tamaño del lote (Batch Size): 1 (para procesar un solo archivo a la vez)
- Salida utilizada: Salida 1 (hacia la descarga)
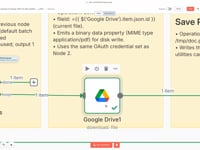
04 Paso 04Descargar el CV desde Google Drive.
Esta acción descarga el archivo PDF del CV desde tu carpeta de Google Drive, utilizando el ID del archivo obtenido en el loop.
➡️ Configuración:
- Módulo: Google Drive
- Operación: Descargar un archivo
- Archivo: ID dinámico del archivo (proveniente del loop)
- Autenticación: Tu propia cuenta de Google conectada a n8n
💡 También puedes reemplazar esta fuente por un disparador de Gmail, una API o cualquier otro sistema que reciba CVs.
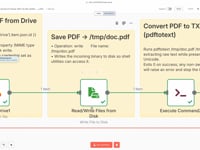
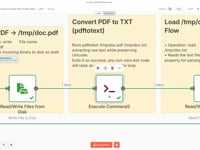
05 Paso 05Guardar el PDF localmente.
Se guarda el archivo PDF en el servidor en una ruta temporal (
/tmp/doc.pdf) para poder utilizarlo con un comando de extracción de texto.Parámetros- Archivo: /tmp/doc.pdf
- Contenido: Datos binarios del PDF descargado
06 Paso 06Extraer el texto del CV (PDFtoText).
En este paso se utiliza el comando
pdftotext(proporcionado por Poppler) para convertir el PDF en un archivo de texto plano que el agente IA pueda leer. Este comando debe estar instalado en tu servidor.➡️ Comando ejecutado:
pdftotext /tmp/doc.pdf /tmp/doc.txt💡 Si no sabes cómo instalar este comando, pide ayuda a ChatGPT según tu sistema (Linux, Docker, Mac…), o contáctanos para asistencia.
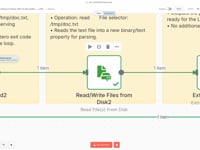
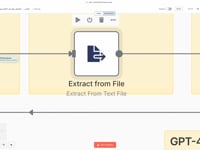
07 Paso 07Leer el contenido del archivo de texto.
Leemos el archivo
/tmp/doc.txtgenerado porpdftotext. El contenido se carga en n8n para enviarlo al agente IA en el siguiente paso.08 Paso 08Preparar el Texto para el Análisis.
Esta etapa limpia y estructura el contenido de texto bruto para que pueda ser analizado correctamente por el agente IA. El texto procesado estará disponible en
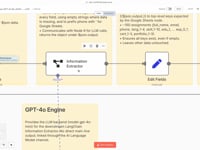
$json.data.09 Paso 09Analizar el CV con un Agente IA (GPT-4o).
El contenido de texto se envía a un agente IA basado en GPT-4o a través de LangChain. Extrae toda la información clave del CV, como nombre, correo electrónico, experiencia, habilidades y más.
➡️ Prompt: estructura fija, nombres de columnas predefinidos, apóstrofes añadidos a los números para compatibilidad con Google Sheets.
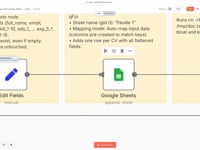
10 Paso 10Aplanar la estructura de datos.
Convertimos el JSON devuelto por el agente IA en una estructura plana compatible con la importación automática en Google Sheets. Cada propiedad (por ejemplo,
lang_1,edu_1_degree) está mapeada explícitamente.💡 Si quieres enviar los datos a otro lugar (Notion, Airtable, base de datos SQL…), puedes adaptar fácilmente este bloque.
11 Paso 11Añadir los Datos Estructurados a Google Sheets.
La información extraída se añade automáticamente como una nueva fila en tu Google Sheet. Cada columna corresponde a un campo claramente definido del CV.
➡️ Conexión : Google Sheets conectado a tu cuenta
💡 También puedes modificar este paso para enviar los datos a Notion, Airtable o cualquier otra base de datos.
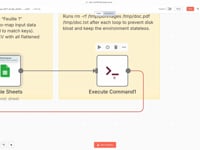
12 Paso 12Limpiar el Servidor.
Este comando elimina todos los archivos temporales (
/tmp/doc.pdfy/tmp/doc.txt) después de cada ciclo para mantener el entorno limpio.➡️ Comando:
rm -rf /tmp/doc.pdf /tmp/doc.txt

Consigue el JSON n8n listo para importar + la guía
Deja tu email y te enviamos el escenario completo.
- JSON n8n listo para importar
- Guía de setup escrita
- Tutorial en video incluido
Por qué Extraer Automáticamente la Información de un CV es Esencial para tu Proceso de Reclutamiento
Gestionar eficientemente las candidaturas o perfiles en tu CRM o ATS es fundamental para automatizar tu proceso de reclutamiento y evitar pérdidas de información. Analizar manualmente los CV en PDF consume tiempo, retrasa la toma de decisiones e introduce errores humanos. Problemas comunes en la extracción manual: Información faltante o mal registrada (emails, experiencia, idiomas…) Pérdida de tiempo copiando y pegando cada CV en un archivo o base de datos. Dificultad para filtrar y clasificar perfiles según criterios específicos. Retrasos en el procesamiento de candidaturas y oportunidades perdidas. Ventajas de extraer automáticamente los datos de los CV: Estructuración limpia y estandarizada de todos los perfiles recibidos. Ahorro significativo de tiempo en la selección y calificación de candidatos. Automatización fluida con Google Sheets, Notion, Airtable o tu CRM. Posibilidad de activar acciones personalizadas (envío de emails, scoring, etiquetado, etc.). Automatizando la extracción de información desde CV en PDF con un agente IA, eliminas tareas tediosas, aseguras la fiabilidad de tus datos y ganas en rapidez. Este escenario n8n se convierte en un activo estratégico para escalar tu proceso de reclutamiento sin esfuerzo.
La automatización completa, en tu bandeja.
JSON n8n, guía escrita y tutorial en video, todo para desplegar en menos de 15 minutos.
- Escenario n8n JSON completo
- Documentación de setup paso a paso
- Tutorial en video completo